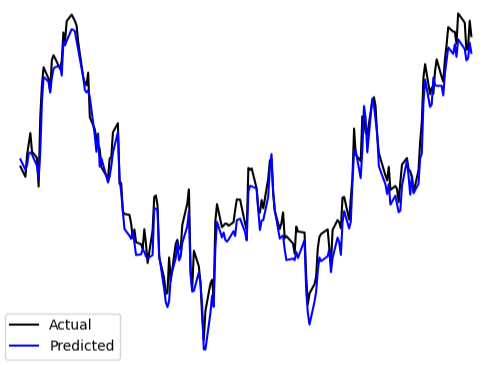
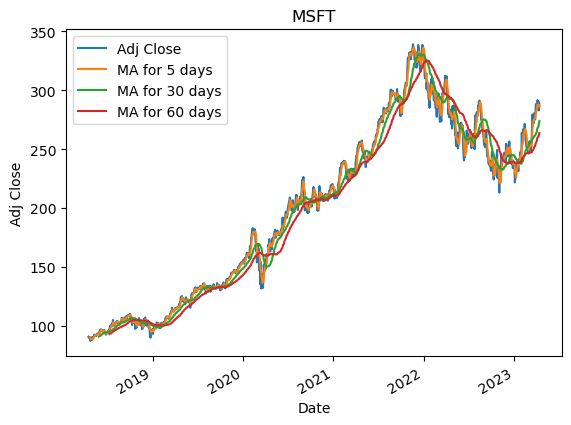
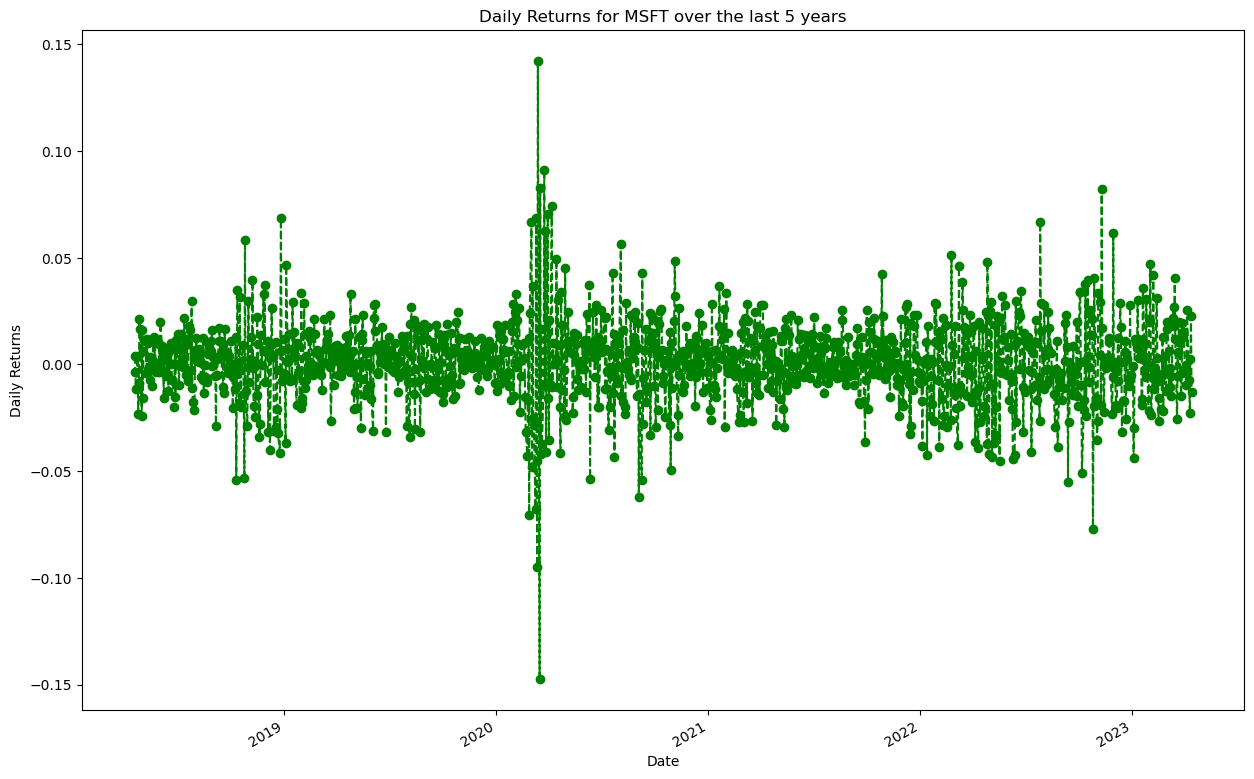
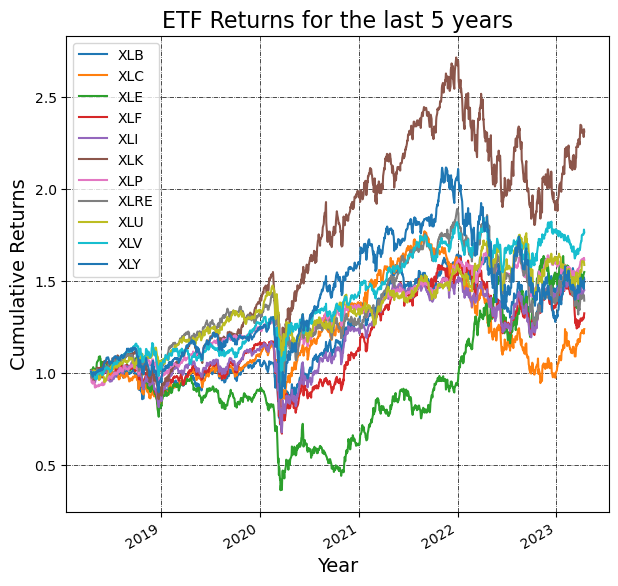
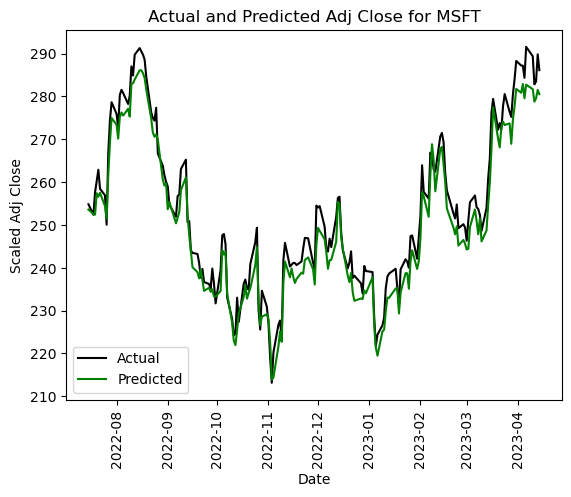
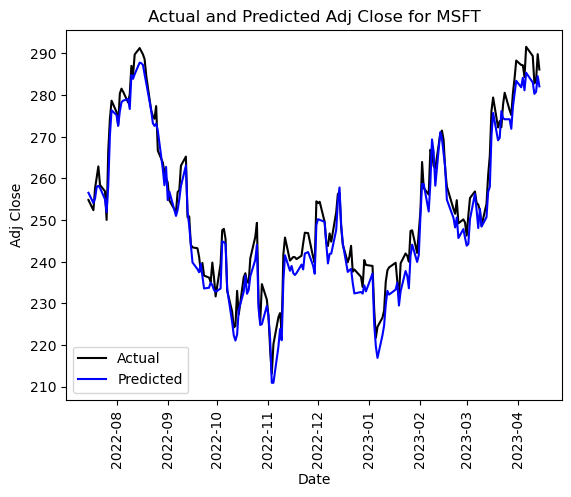
After extensive analysis and model evaluation, we have chosen the Random Forest Regression (RFR) as the final model for predicting stock prices in our project. This decision was driven by several key factors that align with the demands of our dataset and the complexities inherent in financial forecasting.
The Random Forest Regression model demonstrated a high regression confidence of 96%, ensuring its reliability in making accurate predictions across our five-year dataset. Given the volume of data and the non-linear relationships present in stock price movements, Random Forest is certainly the most adapt for this task. It efficiently handles large datasets and is great for capturing complex interactions between variables, such as the relationships between stock price predictors and the adjusted close price.
Another significant advantage of the Random Forest model is its robustness to overfitting. Overfitting is a common challenge in machine learning, where a model may perform well on training data but fail to generalize to unseen data. The ensemble approach of Random Forest, which aggregates multiple decision trees, reduces this risk, ensuring that the model remains effective when applied to new data.
While the Support Vector Regression (SVR) model achieved a lower Mean Squared Error (MSE), the MSE of the Random Forest Regression remains within an acceptable range for our purposes. Considering its strengths in handling non-linear relationships, processing large datasets, and preventing overfitting, we believe the Random Forest Regression model is the most appropriate and reliable choice for this project.
To further support our decision, a feature importance analysis was conducted, revealing that the 'High' stock price is the most influential predictor, accounting for nearly 55% of the importance. This was followed by the 'Low' price at around 40%, while the 'Open' price and 'Volume' had significantly less impact. This analysis not only validates the effectiveness of the Random Forest model but also provides valuable insights into which factors most significantly affect stock price predictions. Below is the feature importance graph.
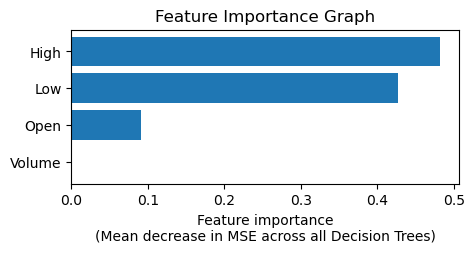
In conclusion, the Random Forest Regression model stands out as the best-suited model for our stock price prediction task. Its high accuracy, ability to capture complex patterns, and resistance against overfitting make it a reliable tool for financial forecasting. The insights gained from this model can be used for more informed decision-making in stock trading and investment strategies.