Objective
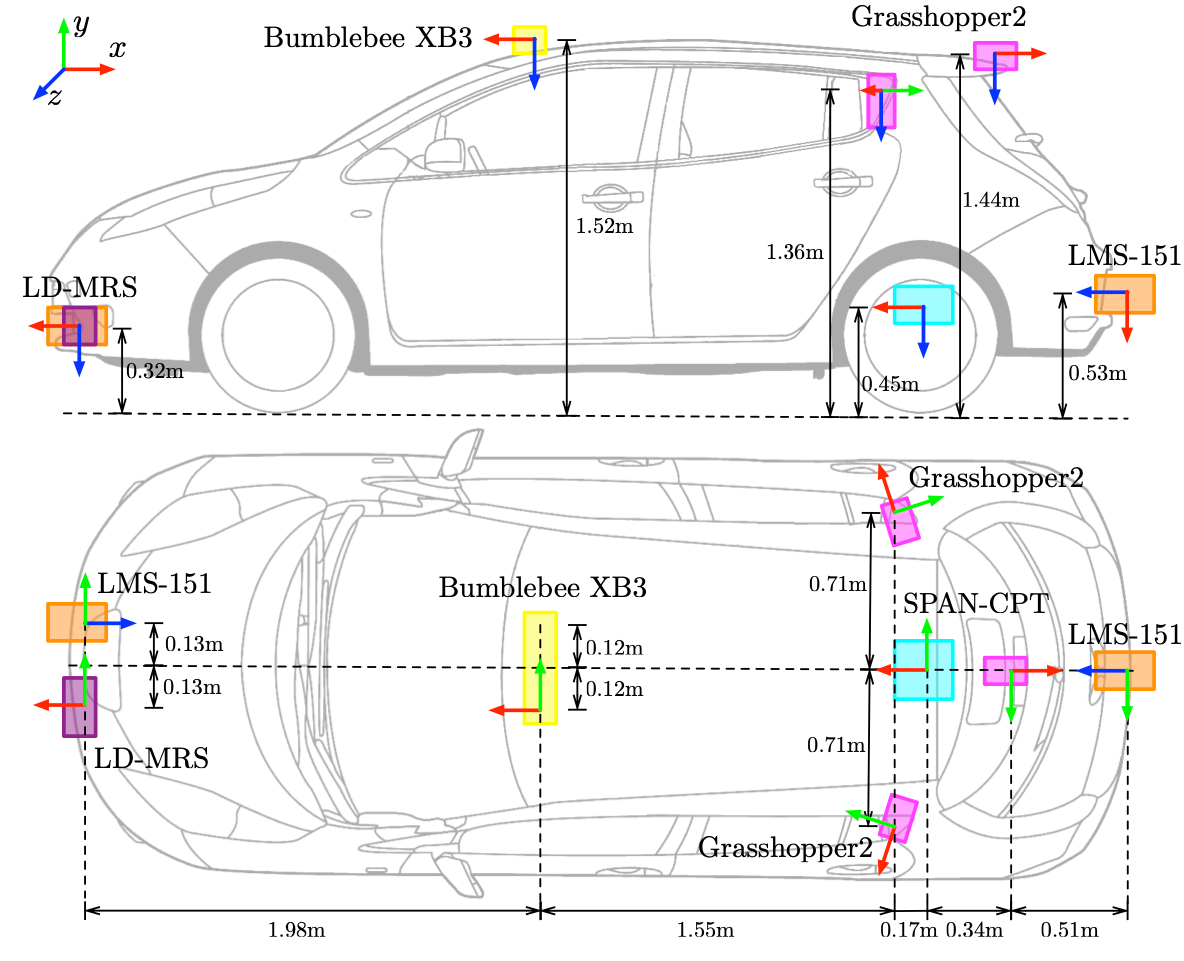
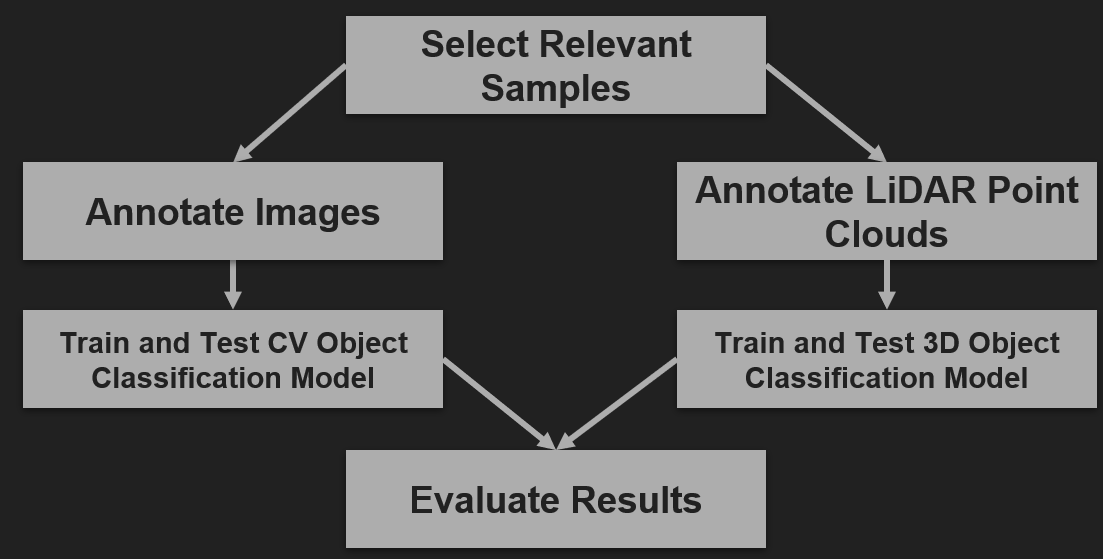
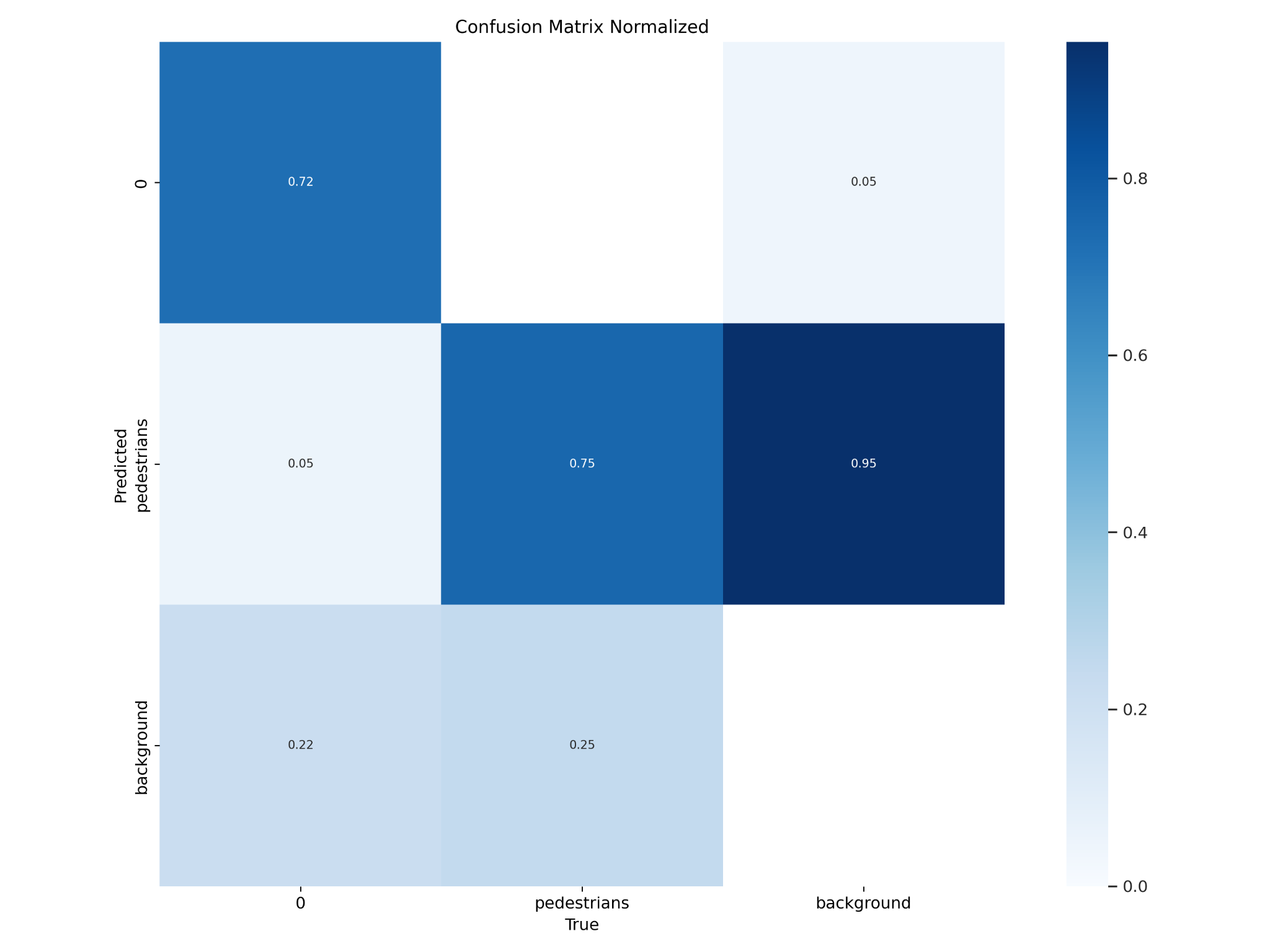
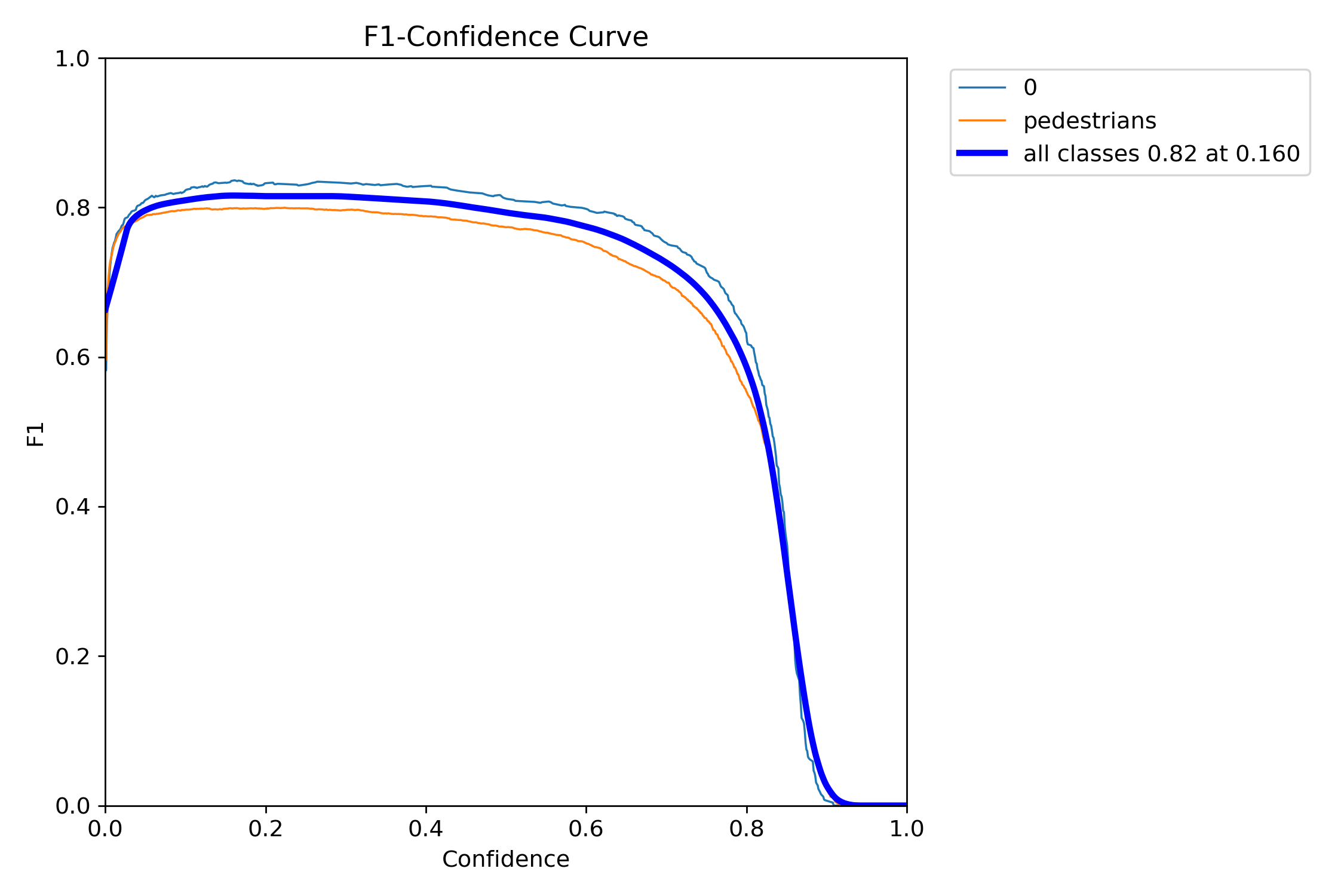
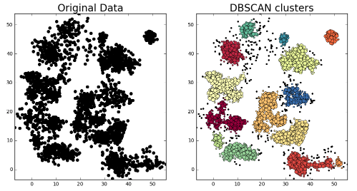
The objective of this project is to evaluate pedestrian detection techniques for autonomous driving by comparing the effectiveness of 2D LiDAR-based clustering and a custom YOLOv11 computer vision model. By integrating data from LiDAR, GPS/INS, and stereo cameras, the project aims to analyze the classification accuracy, robustness, and real-time performance in various environmental conditions, providing insights into the potential for sensor fusion and advanced detection methods in autonomous vehicle navigation.